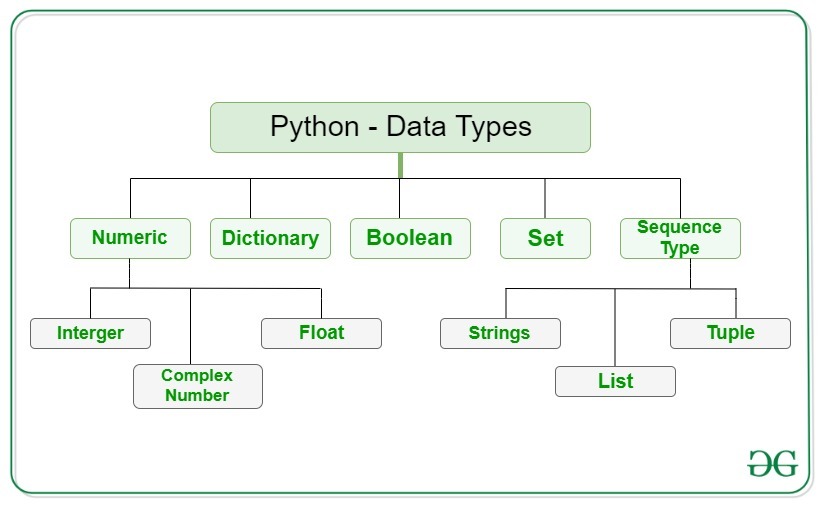
DATA TYPE
- Data type
What is Python type() Function?
To define the values of various data types and check their data types we use the type() function. Consider the following examples.
Python3
Numeric Data Type in Python
The numeric data type in Python represents the data that has a numeric value. A numeric value can be an integer, a floating number, or even a complex number. These values are defined as Python int, Python float, and Python complex classes in Python.
- Integers – This value is represented by int class. It contains positive or negative whole numbers (without fractions or decimals). In Python, there is no limit to how long an integer value can be.
- Float – This value is represented by the float class. It is a real number with a floating-point representation. It is specified by a decimal point. Optionally, the character e or E followed by a positive or negative integer may be appended to specify scientific notation.
- Complex Numbers – Complex number is represented by a complex class. It is specified as (real part) + (imaginary part)j. For example – 2+3j
Note – type() function is used to determine the type of data type.
Python3
Output:
Type of a: <class 'int'> Type of b: <class 'float'> Type of c: <class 'complex'>
Sequence Data Type in Python
The sequence Data Type in Python is the ordered collection of similar or different data types. Sequences allow storing of multiple values in an organized and efficient fashion. There are several sequence types in Python –
String Data Type
Strings in Python are arrays of bytes representing Unicode characters. A string is a collection of one or more characters put in a single quote, double-quote, or triple-quote. In python there is no character data type, a character is a string of length one. It is represented by str class.
Creating String
Strings in Python can be created using single quotes or double quotes or even triple quotes.
Python3
Output:
String with the use of Single Quotes: Welcome to the Geeks World String with the use of Double Quotes: I'm a Geek <class 'str'> String with the use of Triple Quotes: I'm a Geek and I live in a world of "Geeks" <class 'str'> Creating a multiline String: Geeks For LifeAccessing elements of String
In Python, individual characters of a String can be accessed by using the method of Indexing. Negative Indexing allows negative address references to access characters from the back of the String, e.g. -1 refers to the last character, -2 refers to the second last character, and so on.
Python3
Output:
Initial String: GeeksForGeeks First character of String is: G Last character of String is: s
List Data Type
Lists are just like arrays, declared in other languages which is an ordered collection of data. It is very flexible as the items in a list do not need to be of the same type.
Creating List
Lists in Python can be created by just placing the sequence inside the square brackets[].
Python3
Output:
Initial blank List: [] List with the use of String: ['GeeksForGeeks'] List containing multiple values: Geeks Geeks Multi-Dimensional List: [['Geeks', 'For'], ['Geeks']]
Python Access List Items
In order to access the list items refer to the index number. Use the index operator [ ] to access an item in a list. In Python, negative sequence indexes represent positions from the end of the array. Instead of having to compute the offset as in List[len(List)-3], it is enough to just write List[-3]. Negative indexing means beginning from the end, -1 refers to the last item, -2 refers to the second-last item, etc.
Python3
Output:
Accessing element from the list Geeks Geeks Accessing element using negative indexing Geeks Geeks
Note – To know more about Lists, refer to Python List.
Tuple Data Type
Just like a list, a tuple is also an ordered collection of Python objects. The only difference between a tuple and a list is that tuples are immutable i.e. tuples cannot be modified after it is created. It is represented by a tuple class.
Creating a Tuple
In Python, tuples are created by placing a sequence of values separated by a ‘comma’ with or without the use of parentheses for grouping the data sequence. Tuples can contain any number of elements and of any datatype (like strings, integers, lists, etc.). Note: Tuples can also be created with a single element, but it is a bit tricky. Having one element in the parentheses is not sufficient, there must be a trailing ‘comma’ to make it a tuple.
Python3
Output:
Initial empty Tuple: () Tuple with the use of String: ('Geeks', 'For') Tuple using List: (1, 2, 4, 5, 6) Tuple with the use of function: ('G', 'e', 'e', 'k', 's') Tuple with nested tuples: ((0, 1, 2, 3), ('python', 'geek'))Note – The creation of a Python tuple without the use of parentheses is known as Tuple Packing.
Access Tuple Items
In order to access the tuple items refer to the index number. Use the index operator [ ] to access an item in a tuple. The index must be an integer. Nested tuples are accessed using nested indexing.
Python3
Output:
First element of tuple 1 Last element of tuple 5 Third last element of tuple 3
Note – To know more about tuples, refer to Python Tuples.
Boolean Data Type in Python
Data type with one of the two built-in values, True or False. Boolean objects that are equal to True are truthy (true), and those equal to False are falsy (false). But non-Boolean objects can be evaluated in a Boolean context as well and determined to be true or false. It is denoted by the class bool.
Note – True and False with capital ‘T’ and ‘F’ are valid booleans otherwise python will throw an error.
Python3
Output:
<class 'bool'> <class 'bool'>
Traceback (most recent call last): File "/home/7e8862763fb66153d70824099d4f5fb7.py", line 8, in print(type(true)) NameError: name 'true' is not definedSet Data Type in Python
In Python, a Set is an unordered collection of data types that is iterable, mutable and has no duplicate elements. The order of elements in a set is undefined though it may consist of various elements.
Create a Set in Python
Sets can be created by using the built-in set() function with an iterable object or a sequence by placing the sequence inside curly braces, separated by a ‘comma’. The type of elements in a set need not be the same, various mixed-up data type values can also be passed to the set.
Python3
Output:
Initial blank Set: set() Set with the use of String: {'F', 'o', 'G', 's', 'r', 'k', 'e'} Set with the use of List: {'Geeks', 'For'} Set with the use of Mixed Values {1, 2, 4, 6, 'Geeks', 'For'}Access Set Items
Set items cannot be accessed by referring to an index, since sets are unordered the items has no index. But you can loop through the set items using a for loop, or ask if a specified value is present in a set, by using the in the keyword.
Python3
Output:
Initial set: {'Geeks', 'For'} Elements of set: Geeks For TrueNote – To know more about sets, refer to Python Sets.
Dictionary Data Type in Python
A dictionary in Python is an unordered collection of data values, used to store data values like a map, unlike other Data Types that hold only a single value as an element, a Dictionary holds a key: value pair. Key-value is provided in the dictionary to make it more optimized. Each key-value pair in a Dictionary is separated by a colon : , whereas each key is separated by a ‘comma’.
Create a Dictionary
In Python, a Dictionary can be created by placing a sequence of elements within curly {} braces, separated by ‘comma’. Values in a dictionary can be of any datatype and can be duplicated, whereas keys can’t be repeated and must be immutable. The dictionary can also be created by the built-in function dict(). An empty dictionary can be created by just placing it in curly braces{}. Note – Dictionary keys are case sensitive, the same name but different cases of Key will be treated distinctly.
Python3
Output:
Empty Dictionary: {} Dictionary with the use of Integer Keys: {1: 'Geeks', 2: 'For', 3: 'Geeks'} Dictionary with the use of Mixed Keys: {1: [1, 2, 3, 4], 'Name': 'Geeks'} Dictionary with the use of dict(): {1: 'Geeks', 2: 'For', 3: 'Geeks'} Dictionary with each item as a pair: {1: 'Geeks', 2: 'For'}Accessing Key-value in Dictionary
In order to access the items of a dictionary refer to its key name. Key can be used inside square brackets. There is also a method called get() that will also help in accessing the element from a dictionary.
Python3
Output:
Accessing a element using key: For Accessing a element using get: Geeks
Creating a String in Python
Strings in Python can be created using single quotes or double quotes or even triple quotes. Let us see how we can define a string in Python.
Example:
In this example, we will demonstrate different ways to create a Python String. We will create a string using single quotes (‘ ‘), double quotes (” “), and triple double quotes (“”” “””). The triple quotes can be used to declare multiline strings in Python.
- Python3
Output:
String with the use of Single Quotes:
Welcome to the Geeks World
String with the use of Double Quotes:
I'm a Geek
String with the use of Triple Quotes:
I'm a Geek and I live in a world of "Geeks"
Creating a multiline String:
Geeks
For
LifeAccessing characters in Python String
In Python, individual characters of a String can be accessed by using the method of Indexing. Indexing allows negative address references to access characters from the back of the String, e.g. -1 refers to the last character, -2 refers to the second last character, and so on.
While accessing an index out of the range will cause an IndexError. Only Integers are allowed to be passed as an index, float or other types that will cause a TypeError.
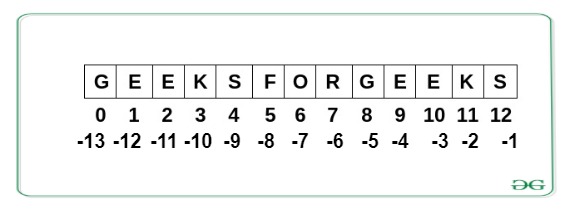
Python String indexing
Example:
In this example, we will define a string in Python and access its characters using positive and negative indexing. The 0th element will be the first character of the string whereas the -1th element is the last character of the string.
- Python3
Output:
Initial String:
GeeksForGeeks
First character of String is:
G
Last cha racter of String is:
sString Slicing
In Python, the String Slicing method is used to access a range of characters in the String. Slicing in a String is done by using a Slicing operator, i.e., a colon (:). One thing to keep in mind while using this method is that the string returned after slicing includes the character at the start index but not the character at the last index.
Example:
In this example, we will use the string-slicing method to extract a substring of the original string. The [3:12] indicates that the string slicing will start from the 3rd index of the string to the 12th index, (12th character not including). We can also use negative indexing in string slicing.
- Python3
Output:
Initial String:
GeeksForGeeks
Slicing characters from 3-12:
ksForGeek
Slicing characters between 3rd and 2nd last character:
ksForGeeReversing a Python String
By accessing characters from a string, we can also reverse strings in Python. We can Reverse a string by using String slicing method.
Example:
In this example, we will reverse a string by accessing the index. We did not specify the first two parts of the slice indicating that we are considering the whole string, from the start index to the last index.
- Python3
Output:
skeegrofskeeg
Example:
We can also reverse a string by using built-in join and reversed functions, and passing the string as the parameter to the reversed() function.
- Python3
Output:
skeegrofskeeg
Deleting/Updating from a String
In Python, the Updation or deletion of characters from a String is not allowed. This will cause an error because item assignment or item deletion from a String is not supported. Although deletion of the entire String is possible with the use of a built-in del keyword. This is because Strings are immutable, hence elements of a String cannot be changed once assigned. Only new strings can be reassigned to the same name.
Updating a character
A character of a string can be updated in Python by first converting the string into a Python List and then updating the element in the list. As lists are mutable in nature, we can update the character and then convert the list back into the String.
Another method is using the string slicing method. Slice the string before the character you want to update, then add the new character and finally add the other part of the string again by string slicing.
Example:
In this example, we are using both the list and the string slicing method to update a character. We converted the String1 to a list, changes its value at a particular element, and then converted it back to a string using the Python string join() method.
In the string-slicing method, we sliced the string up to the character we want to update, concatenated the new character, and finally concatenate the remaining part of the string.
- Python3
Output:
Initial String:
Hello, I'm a Geek
Updating character at 2nd Index:
Heplo, I'm a Geek
Heplo, I'm a GeekUpdating Entire String
As Python strings are immutable in nature, we cannot update the existing string. We can only assign a completely new value to the variable with the same name.
Example:
In this example, we first assign a value to ‘String1’ and then updated it by assigning a completely different value to it. We simply changed its reference.
- Python3
Output:
Initial String:
Hello, I'm a Geek
Updated String:
Welcome to the Geek WorldDeleting a character
Python strings are immutable, that means we cannot delete a character from it. When we try to delete thecharacter using the del keyword, it will generate an error.
- Python3
Output:
Initial String:
Hello, I'm a Geek
Deleting character at 2nd Index:
Traceback (most recent call last):
File "e:\GFG\Python codes\Codes\demo.py", line 9, in <module>
del String1[2]
TypeError: 'str' object doesn't support item deletionBut using slicing we can remove the character from the original string and store the result in a new string.
Example:
In this example, we will first slice the string up to the character that we want to delete and then concatenate the remaining string next from the deleted character.
- Python3
Output:
Initial String:
Hello, I'm a Geek
Deleting character at 2nd Index:
Helo, I'm a GeekDeleting Entire String
Deletion of the entire string is possible with the use of del keyword. Further, if we try to print the string, this will produce an error because the String is deleted and is unavailable to be printed.
- Python3
Error:
Traceback (most recent call last):
File "/home/e4b8f2170f140da99d2fe57d9d8c6a94.py", line 12, in
print(String1)
NameError: name 'String1' is not definedEscape Sequencing in Python
While printing Strings with single and double quotes in it causes SyntaxError because String already contains Single and Double Quotes and hence cannot be printed with the use of either of these. Hence, to print such a String either Triple Quotes are used or Escape sequences are used to print Strings.
Escape sequences start with a backslash and can be interpreted differently. If single quotes are used to represent a string, then all the single quotes present in the string must be escaped and the same is done for Double Quotes.
Example:
- Python3
Output:
Initial String with use of Triple Quotes:
I'm a "Geek"
Escaping Single Quote:
I'm a "Geek"
Escaping Double Quotes:
I'm a "Geek"
Escaping Backslashes:
C:\Python\Geeks\
Tab:
Hi Geeks
New Line:
Python
GeeksExample:
To ignore the escape sequences in a String, r or R is used, this implies that the string is a raw string and escape sequences inside it are to be ignored.
- Python3
Output:
Printing in Octal with the use of Escape Sequences:
Hello
Printing Raw String in Octal Format:
This is \110\145\154\154\157
Printing in HEX with the use of Escape Sequences:
This is Geeks in HEX
Printing Raw String in HEX Format:
This is \x47\x65\x65\x6b\x73 in \x48\x45\x58Formatting of Strings
Strings in Python can be formatted with the use of format() method which is a very versatile and powerful tool for formatting Strings. Format method in String contains curly braces {} as placeholders which can hold arguments according to position or keyword to specify the order.
Example 1:
In this example, we will declare a string which contains the curly braces {} that acts as a placeholders and provide them values to see how string declaration position matters.
- Python3
Output:
Print String in default order:
Geeks For Life
Print String in Positional order:
For Geeks Life
Print String in order of Keywords:
Life For GeeksExample 2:
Integers such as Binary, hexadecimal, etc., and floats can be rounded or displayed in the exponent form with the use of format specifiers.
- Python3
Output:
Binary representation of 16 is
10000
Exponent representation of 165.6458 is
1.656458e+02
one-sixth is :
0.17Example 3:
A string can be left, right, or center aligned with the use of format specifiers, separated by a colon(:). The (<) indicates that the string should be aligned to the left, (>) indicates that the string should be aligned to the right and (^) indicates that the string should be aligned to the center. We can also specify the length in which it should be aligned. For example, (<10) means that the string should be aligned to the left within a field of width of 10 characters.
- Python3
Output:
Left, center and right alignment with Formatting:
|Geeks | for | Geeks|
GeeksforGeeks was founded in 2009 !Example 4:
Old-style formatting was done without the use of the format method by using the % operator
- Python3
Output:
Formatting in 3.2f format:
The value of Integer1 is 12.35
Formatting in 3.4f format:
The value of Integer1 is 12.3457Useful Python String Operations
- Logical Operators on String
- String Formatting using %
- String Template Class
- Split a string
- Python Docstrings
- String slicing
- Find all duplicate characters in string
- Reverse string in Python (5 different ways)
- Python program to check if a string is palindrome or not
Python String constants
Built-In Function
Description
string.ascii_letters Concatenation of the ascii_lowercase and ascii_uppercase constants.
string.ascii_lowercase Concatenation of lowercase letters
string.ascii_uppercase Concatenation of uppercase letters
string.digits Digit in strings
string.hexdigits Hexadigit in strings
string.letters
concatenation of the strings lowercase and uppercase
string.lowercase
A string must contain lowercase letters.
string.octdigits
Octadigit in a string
string.punctuation
ASCII characters having punctuation characters.
string.printable
String of characters which are printable
String.endswith() Returns True if a string ends with the given suffix otherwise returns False
String.startswith() Returns True if a string starts with the given prefix otherwise returns False
String.isdigit() Returns “True” if all characters in the string are digits, Otherwise, It returns “False”.
String.isalpha() Returns “True” if all characters in the string are alphabets, Otherwise, It returns “False”.
string.isdecimal() Returns true if all characters in a string are decimal.
str.format() one of the string formatting methods in Python3, which allows multiple substitutions and value formatting.
String.index Returns the position of the first occurrence of substring in a string
string.uppercase
A string must contain uppercase letters.
string.whitespace A string containing all characters that are considered whitespace.
string.swapcase() Method converts all uppercase characters to lowercase and vice versa of the given string, and returns it
replace() returns a copy of the string where all occurrences of a substring is replaced with another substring.
Deprecated string functions
Built-In Function
Description
string.Isdecimal Returns true if all characters in a string are decimal
String.Isalnum Returns true if all the characters in a given string are alphanumeric.
string.Istitle Returns True if the string is a title cased string
String.partition splits the string at the first occurrence of the separator and returns a tuple.
String.Isidentifier Check whether a string is a valid identifier or not.
String.len Returns the length of the string.
String.rindex Returns the highest index of the substring inside the string if substring is found.
String.Max Returns the highest alphabetical character in a string.
String.min Returns the minimum alphabetical character in a string.
String.splitlines Returns a list of lines in the string.
string.capitalize Return a word with its first character capitalized.
string.expandtabs Expand tabs in a string replacing them by one or more spaces
string.find Return the lowest indexing a sub string.
string.rfind find the highest index.
string.count Return the number of (non-overlapping) occurrences of substring sub in string
string.lower Return a copy of s, but with upper case, letters converted to lower case.
string.split Return a list of the words of the string, If the optional second argument sep is absent or None
string.rsplit() Return a list of the words of the string s, scanning s from the end.
rpartition() Method splits the given string into three parts
string.splitfields
Return a list of the words of the string when only used with two arguments.
string.join Concatenate a list or tuple of words with intervening occurrences of sep.
string.strip() It returns a copy of the string with both leading and trailing white spaces removed
string.lstrip Return a copy of the string with leading white spaces removed.
string.rstrip Return a copy of the string with trailing white spaces removed.
string.swapcase Converts lower case letters to upper case and vice versa.
string.translate Translate the characters using table
string.upper lower case letters converted to upper case.
string.ljust left-justify in a field of given width.
string.rjust Right-justify in a field of given width.
string.center() Center-justify in a field of given width.
string-zfill Pad a numeric string on the left with zero digits until the given width is reached.
string.replace Return a copy of string s with all occurrences of substring old replaced by new.
string.casefold() Returns the string in lowercase which can be used for caseless comparisons.
string.encode Encodes the string into any encoding supported by Python. The default encoding is utf-8.
string.maketrans Returns a translation table usable for str.translate()
- Regular Expressions
- Why Regular Expressions
- Basic Regular Expressions
- More Regular Expressions
- Compiled Regular Expressions
A RegEx is a powerful tool for matching text, based on a pre-defined pattern. It can detect the presence or absence of a text by matching it with a particular pattern, and also can split a pattern into one or more sub-patterns. The Python standard library provides a re module for regular expressions. Its primary function is to offer a search, where it takes a regular expression and a string. Here, it either returns the first match or else none.
- Python3
Output<_sre.SRE_Match object; span=(52, 58), match='portal'> portal Start Index: 52 End Index: 58
Here r character (r’portal’) stands for raw, not RegEx. The raw string is slightly different from a regular string, it won’t interpret the \ character as an escape character. This is because the regular expression engine uses \ character for its own escaping purpose.
Before starting with the Python regex module let’s see how to actually write RegEx using metacharacters or special sequences.
MetaCharacters
To understand the RE analogy, MetaCharacters are useful, important, and will be used in functions of module re. Below is the list of metacharacters.
MetaCharacters Description \ Used to drop the special meaning of character following it [] Represent a character class ^ Matches the beginning $ Matches the end . Matches any character except newline | Means OR (Matches with any of the characters separated by it. ? Matches zero or one occurrence * Any number of occurrences (including 0 occurrences) + One or more occurrences {} Indicate the number of occurrences of a preceding RegEx to match. () Enclose a group of RegEx The group method returns the matching string, and the start and end method provides the starting and ending string index. Apart from this, it has so many other methods, which we will discuss later.
Why RegEx?
Let’s take a moment to understand why we should use Regular expression.
- Data Mining: Regular expression is the best tool for data mining. It efficiently identifies a text in a heap of text by checking with a pre-defined pattern. Some common scenarios are identifying an email, URL, or phone from a pile of text.
- Data Validation: Regular expression can perfectly validate data. It can include a wide array of validation processes by defining different sets of patterns. A few examples are validating phone numbers, emails, etc.
Basic RegEx
Let’s understand some of the basic regular expressions. They are as follows:
- Character Classes
- Rangers
- Negation
- Shortcuts
- Beginning and End of String
- Any Character
Character Classes
Character classes allow you to match a single set of characters with a possible set of characters. You can mention a character class within the square brackets. Let’s consider an example of case-sensitive words.
- Python3
Output['Geeks', 'Geeks', 'geeks']
Ranges
The range provides the flexibility to match a text with the help of a range pattern such as a range of numbers(0 to 9), a range of characters (A to Z), and so on. The hyphen character within the character class represents a range.
- Python3
OutputRange <_sre.SRE_Match object; span=(0, 1), match='x'>
Negation
Negation inverts a character class. It will look for a match except for the inverted character or range of inverted characters mentioned in the character class.
- Python3
OutputNone
In the above case, we have inverted the character class that ranges from a to z. If we try to match a character within the mentioned range, the regular expression engine returns None.
Let’s consider another example
- Python3
OutputNone
Here it accepts any other character that follows G, other than e.
List of special sequences
Special Sequence Description Examples \A Matches if the string begins with the given character \Afor for geeks for the world \b Matches if the word begins or ends with the given character. \b(string) will check for the beginning of the word and (string)\b will check for the ending of the word. \bge geeks get \B It is the opposite of the \b i.e. the string should not start or end with the given regex. \Bge together forge \d Matches any decimal digit, this is equivalent to the set class [0-9] \d 123 gee1 \D Matches any non-digit character, this is equivalent to the set class [^0-9] \D geeks geek1 \s Matches any whitespace character. \s gee ks a bc a \S Matches any non-whitespace character \S a bd abcd \w Matches any alphanumeric character, this is equivalent to the class [a-zA-Z0-9_]. \w 123 geeKs4 \W Matches any non-alphanumeric character. \W >$ gee<> \Z Matches if the string ends with the given regex ab\Z abcdab abababab Shortcuts
Let’s discuss some of the shortcuts provided by the regular expression engine.
- \w – matches a word character
- \d – matches digit character
- \s – matches whitespace character (space, tab, newline, etc.)
- \b – matches a zero-length character
- Python3
OutputGeeks: <_sre.SRE_Match object; span=(0, 5), match='Geeks'> GeeksforGeeks: None
Beginning and End of String
The ^ character chooses the beginning of a string and the $ character chooses the end of a string.
- Python3
OutputBeg. of String: None Beg. of String: <_sre.SRE_Match object; span=(0, 4), match='Geek'> End of String: <_sre.SRE_Match object; span=(31, 36), match='Geeks'>
Any Character
The . character represents any single character outside a bracketed character class.
- Python3
OutputAny Character <_sre.SRE_Match object; span=(0, 6), match='python'>
More RegEx
Some of the other regular expressions are as follows:
- Optional Characters
- Repetition
- Shorthand
- Grouping
- Lookahead
- Substitution
Optional Characters
Regular expression engine allows you to specify optional characters using the ? character. It allows a character or character class either to present once or else not to occur. Let’s consider the example of a word with an alternative spelling – color or colour.
- Python3
OutputColor <_sre.SRE_Match object; span=(0, 5), match='color'> Colour <_sre.SRE_Match object; span=(0, 6), match='colour'>
Repetition
Repetition enables you to repeat the same character or character class. Consider an example of a date that consists of day, month, and year. Let’s use a regular expression to identify the date (mm-dd-yyyy).
- Python3
OutputDate{mm-dd-yyyy}: <_sre.SRE_Match object; span=(0, 10), match='18-08-2020'>Here, the regular expression engine checks for two consecutive digits. Upon finding the match, it moves to the hyphen character. After then, it checks the next two consecutive digits, and the process is repeated.
Let’s discuss three other regular expressions under repetition.
Repetition ranges
The repetition range is useful when you have to accept one or more formats. Consider a scenario where both three digits, as well as four digits, are accepted. Let’s have a look at the regular expression.
- Python3
OutputThree Digit: <_sre.SRE_Match object; span=(0, 3), match='189'> Four Digit: <_sre.SRE_Match object; span=(0, 4), match='2145'>
Open-Ended Ranges
There are scenarios where there is no limit for a character repetition. In such scenarios, you can set the upper limit as infinitive. A common example is matching street addresses. Let’s have a look
- Python3
Output<_sre.SRE_Match object; span=(0, 1), match='5'>
Shorthand
Shorthand characters allow you to use + character to specify one or more ({1,}) and * character to specify zero or more ({0,}.
- Python3
Output<_sre.SRE_Match object; span=(0, 1), match='5'>
Grouping
Grouping is the process of separating an expression into groups by using parentheses, and it allows you to fetch each individual matching group.
- Python3
Output<_sre.SRE_Match object; span=(0, 10), match='26-08-2020'>
Let’s see some of its functionality.
Return the entire match
The re module allows you to return the entire match using the group() method
- Python3
Output26-08-2020
Return a tuple of matched groups
You can use groups() method to return a tuple that holds individual matched groups
- Python3
Output('26', '08', '2020')Retrieve a single group
Upon passing the index to a group method, you can retrieve just a single group.
- Python3
Output2020
Name your groups
The re module allows you to name your groups. Let’s look into the syntax.
- Python3
Output08
Individual match as a dictionary
We have seen how regular expression provides a tuple of individual groups. Not only tuple, but it can also provide individual match as a dictionary in which the name of each group acts as the dictionary key.
- Python3
Output{'dd': '26', 'mm': '08', 'yyyy': '2020'}Lookahead
In the case of a negated character class, it won’t match if a character is not present to check against the negated character. We can overcome this case by using lookahead; it accepts or rejects a match based on the presence or absence of content.
- Python3
Outputnegation: None lookahead: <_sre.SRE_Match object; span=(5, 6), match='n'>
Lookahead can also disqualify the match if it is not followed by a particular character. This process is called a positive lookahead, and can be achieved by simply replacing ! character with = character.
- Python3
Outputpositive lookahead <_sre.SRE_Match object; span=(5, 6), match='n'>
Substitution
The regular expression can replace the string and returns the replaced one using the re.sub method. It is useful when you want to avoid characters such as /, -, ., etc. before storing it to a database. It takes three arguments:
- the regular expression
- the replacement string
- the source string being searched
Let’s have a look at the below code that replaces – character from a credit card number.
- Python3
Output1111222233334444
Compiled RegEx
The Python regular expression engine can return a compiled regular expression(RegEx) object using compile function. This object has its search method and sub-method, where a developer can reuse it when in need.
- Python3
Output
compiled reg expr <_sre.SRE_Match object; span=(0, 10), match=’26-08-2020′> 26.08.2020
\ – Backslash
The backslash (\) makes sure that the character is not treated in a special way. This can be considered a way of escaping metacharacters. For example, if you want to search for the dot(.) in the string then you will find that dot(.) will be treated as a special character as is one of the metacharacters (as shown in the above table). So for this case, we will use the backslash(\) just before the dot(.) so that it will lose its specialty. See the below example for a better understanding.
Example:
- Python3
Output<re.Match object; span=(0, 1), match='g'> <re.Match object; span=(5, 6), match='.'>
[] – Square Brackets
Square Brackets ([]) represent a character class consisting of a set of characters that we wish to match. For example, the character class [abc] will match any single a, b, or c.
We can also specify a range of characters using – inside the square brackets. For example,
- [0, 3] is sample as [0123]
- [a-c] is same as [abc]
We can also invert the character class using the caret(^) symbol. For example,
- [^0-3] means any number except 0, 1, 2, or 3
- [^a-c] means any character except a, b, or c
Example:
- Python3
Output['h', 'e', 'i', 'c', 'k', 'b', 'f', 'j', 'm', 'e', 'h', 'e', 'l', 'a', 'd', 'g']
OutputStart Index: 34 End Index: 40
The above code gives the starting index and the ending index of the string portal.
Note: Here r character (r’portal’) stands for raw, not regex. The raw string is slightly different from a regular string, it won’t interpret the \ character as an escape character. This is because the regular expression engine uses \ character for its own escaping purpose.
Before starting with the Python regex module let’s see how to actually write regex using metacharacters or special sequences.
MetaCharacters
To understand the RE analogy, MetaCharacters are useful, important, and will be used in functions of module re. Below is the list of metacharacters.
MetaCharacters
Description
\
Used to drop the special meaning of character following it
[]
Represent a character class
^
Matches the beginning
$
Matches the end
.
Matches any character except newline
|
Means OR (Matches with any of the characters separated by it.
?
Matches zero or one occurrence
*
Any number of occurrences (including 0 occurrences)
+
One or more occurrences
{}
Indicate the number of occurrences of a preceding regex to match.
()
Enclose a group of Regex
Let’s discuss each of these metacharacters in detail
\ – Backslash
The backslash (\) makes sure that the character is not treated in a special way. This can be considered a way of escaping metacharacters. For example, if you want to search for the dot(.) in the string then you will find that dot(.) will be treated as a special character as is one of the metacharacters (as shown in the above table). So for this case, we will use the backslash(\) just before the dot(.) so that it will lose its specialty. See the below example for a better understanding.
Example:
- Python3
Output<re.Match object; span=(0, 1), match='g'> <re.Match object; span=(5, 6), match='.'>
[] – Square Brackets
Square Brackets ([]) represent a character class consisting of a set of characters that we wish to match. For example, the character class [abc] will match any single a, b, or c.
We can also specify a range of characters using – inside the square brackets. For example,
- [0, 3] is sample as [0123]
- [a-c] is same as [abc]
We can also invert the character class using the caret(^) symbol. For example,
- [^0-3] means any number except 0, 1, 2, or 3
- [^a-c] means any character except a, b, or c
Example:
- Python3
Output['h', 'e', 'i', 'c', 'k', 'b', 'f', 'j', 'm', 'e', 'h', 'e', 'l', 'a', 'd', 'g']
^ – Caret
Caret (^) symbol matches the beginning of the string i.e. checks whether the string starts with the given character(s) or not. For example –
- ^g will check if the string starts with g such as geeks, globe, girl, g, etc.
- ^ge will check if the string starts with ge such as geeks, geeksforgeeks, etc.
Example:
- Python3
OutputMatched: The quick brown fox Matched: The lazy dog Not matched: A quick brown fox
$ – Dollar
Dollar($) symbol matches the end of the string i.e checks whether the string ends with the given character(s) or not. For example –
- s$ will check for the string that ends with a such as geeks, ends, s, etc.
- ks$ will check for the string that ends with ks such as geeks, geeksforgeeks, ks, etc.
Example:
- Python3
OutputMatch found!
. – Dot
Dot(.) symbol matches only a single character except for the newline character (\n). For example –
- a.b will check for the string that contains any character at the place of the dot such as acb, acbd, abbb, etc
- .. will check if the string contains at least 2 characters
Example:
- Python3
OutputMatch found!
| – Or
Or symbol works as the or operator meaning it checks whether the pattern before or after the or symbol is present in the string or not. For example –
- a|b will match any string that contains a or b such as acd, bcd, abcd, etc.
? – Question Mark
The question mark (?) is a quantifier in regular expressions that indicates that the preceding element should be matched zero or one time. It allows you to specify that the element is optional, meaning it may occur once or not at all. For example,
- ab?c will be matched for the string ac, acb, dabc but will not be matched for abbc because there are two b. Similarly, it will not be matched for abdc because b is not followed by c.
* – Star
Star (*) symbol matches zero or more occurrences of the regex preceding the * symbol. For example –
- ab*c will be matched for the string ac, abc, abbbc, dabc, etc. but will not be matched for abdc because b is not followed by c.
+ – Plus
Plus (+) symbol matches one or more occurrences of the regex preceding the + symbol. For example –
- ab+c will be matched for the string abc, abbc, dabc, but will not be matched for ac, abdc, because there is no b in ac and b, is not followed by c in abdc.
{m, n} – Braces
Braces match any repetitions preceding regex from m to n both inclusive. For example –
- a{2, 4} will be matched for the string aaab, baaaac, gaad, but will not be matched for strings like abc, bc because there is only one a or no a in both the cases.
(<regex>) – Group
Group symbol is used to group sub-patterns. For example –
- (a|b)cd will match for strings like acd, abcd, gacd, etc.
Special Sequences
Special sequences do not match for the actual character in the string instead it tells the specific location in the search string where the match must occur. It makes it easier to write commonly used patterns.
List of special sequences
Special Sequence
Description
Examples
\A
Matches if the string begins with the given character
\Afor
for geeks
for the world
\b
Matches if the word begins or ends with the given character. \b(string) will check for the beginning of the word and (string)\b will check for the ending of the word.
\bge
geeks
get
\B
It is the opposite of the \b i.e. the string should not start or end with the given regex.
\Bge
together
forge
\d
Matches any decimal digit, this is equivalent to the set class [0-9]
\d
123
gee1
\D
Matches any non-digit character, this is equivalent to the set class [^0-9]
\D
geeks
geek1
\s
Matches any whitespace character.
\s
gee ks
a bc a
\S
Matches any non-whitespace character
\S
a bd
abcd
\w
Matches any alphanumeric character, this is equivalent to the class [a-zA-Z0-9_].
\w
123
geeKs4
\W
Matches any non-alphanumeric character.
\W
>$
gee<>
\Z
Matches if the string ends with the given regex
ab\Z
abcdab
abababab
Regex Module in Python
Python has a module named re that is used for regular expressions in Python. We can import this module by using the import statement.
Example: Importing re module in Python
- Python3
Let’s see various functions provided by this module to work with regex in Python.
re.findall()
Return all non-overlapping matches of pattern in string, as a list of strings. The string is scanned left-to-right, and matches are returned in the order found.
Example: Finding all occurrences of a pattern
- Python3
Output['123456789', '987654321']
re.compile()
Regular expressions are compiled into pattern objects, which have methods for various operations such as searching for pattern matches or performing string substitutions.
Example 1:
- Python
Output['e', 'a', 'd', 'b', 'e', 'a']
Output:
['e', 'a', 'd', 'b', 'e', 'a']Understanding the Output:
- First occurrence is ‘e’ in “Aye” and not ‘A’, as it is Case Sensitive.
- Next Occurrence is ‘a’ in “said”, then ‘d’ in “said”, followed by ‘b’ and ‘e’ in “Gibenson”, the Last ‘a’ matches with “Stark”.
- Metacharacter backslash ‘\’ has a very important role as it signals various sequences. If the backslash is to be used without its special meaning as metacharacter, use’\\’
Example 2: Set class [\s,.] will match any whitespace character, ‘,’, or, ‘.’ .
- Python
Output['1', '1', '4', '1', '8', '8', '6'] ['11', '4', '1886']
Output:
['1', '1', '4', '1', '8', '8', '6'] ['11', '4', '1886']Example 3:
- Python
Output['H', 'e', 's', 'a', 'i', 'd', 'i', 'n', 's', 'o', 'm', 'e', '_', 'l', 'a', 'n', 'g'] ['I', 'went', 'to', 'him', 'at', '11', 'A', 'M', 'he', 'said', 'in', 'some_language'] [' ', ' ', '*', '*', '*', ' ', ' ', '.']
Output:
['H', 'e', 's', 'a', 'i', 'd', 'i', 'n', 's', 'o', 'm', 'e', '_', 'l', 'a', 'n', 'g'] ['I', 'went', 'to', 'him', 'at', '11', 'A', 'M', 'he', 'said', 'in', 'some_language'] [' ', ' ', '*', '*', '*', ' ', ' ', '.']Example 4:
- Python
Output['ab', 'abb', 'a', 'abbb']
Output:
['ab', 'abb', 'a', 'abbb']Understanding the Output:
- Our RE is ab*, which ‘a’ accompanied by any no. of ‘b’s, starting from 0.
- Output ‘ab’, is valid because of single ‘a’ accompanied by single ‘b’.
- Output ‘abb’, is valid because of single ‘a’ accompanied by 2 ‘b’.
- Output ‘a’, is valid because of single ‘a’ accompanied by 0 ‘b’.
- Output ‘abbb’, is valid because of single ‘a’ accompanied by 3 ‘b’.
re.split()
Split string by the occurrences of a character or a pattern, upon finding that pattern, the remaining characters from the string are returned as part of the resulting list.
Syntax :
re.split(pattern, string, maxsplit=0, flags=0)The First parameter, pattern denotes the regular expression, string is the given string in which pattern will be searched for and in which splitting occurs, maxsplit if not provided is considered to be zero ‘0’, and if any nonzero value is provided, then at most that many splits occur. If maxsplit = 1, then the string will split once only, resulting in a list of length 2. The flags are very useful and can help to shorten code, they are not necessary parameters, eg: flags = re.IGNORECASE, in this split, the case, i.e. the lowercase or the uppercase will be ignored.
Example 1:
- Python
Output['Words', 'words', 'Words'] ['Word', 's', 'words', 'Words'] ['On', '12th', 'Jan', '2016', 'at', '11', '02', 'AM'] ['On ', 'th Jan ', ', at ', ':', ' AM']
Output:
['Words', 'words', 'Words'] ['Word', 's', 'words', 'Words'] ['On', '12th', 'Jan', '2016', 'at', '11', '02', 'AM'] ['On ', 'th Jan ', ', at ', ':', ' AM']Example 2:
- Python
Output['On ', 'th Jan 2016, at 11:02 AM'] ['', 'y, ', 'oy oh ', 'oy, ', 'om', ' h', 'r', ''] ['A', 'y, Boy oh ', 'oy, ', 'om', ' h', 'r', '']
Output:
['On ', 'th Jan 2016, at 11:02 AM'] ['', 'y, ', 'oy oh ', 'oy, ', 'om', ' h', 'r', ''] ['A', 'y, Boy oh ', 'oy, ', 'om', ' h', 'r', '']re.sub()
The ‘sub’ in the function stands for SubString, a certain regular expression pattern is searched in the given string(3rd parameter), and upon finding the substring pattern is replaced by repl(2nd parameter), count checks and maintains the number of times this occurs.
Syntax:
re.sub(pattern, repl, string, count=0, flags=0)Example 1:
- Python
OutputS~*ject has ~*er booked already S~*ject has Uber booked already S~*ject has Uber booked already Baked Beans & Spam
Output
S~*ject has ~*er booked already S~*ject has Uber booked already S~*ject has Uber booked already Baked Beans & Spamre.subn()
subn() is similar to sub() in all ways, except in its way of providing output. It returns a tuple with a count of the total of replacement and the new string rather than just the string.
Syntax:
re.subn(pattern, repl, string, count=0, flags=0)Example:
- Python
Output('S~*ject has Uber booked already', 1) ('S~*ject has ~*er booked already', 2) 2 S~*ject has ~*er booked alreadyOutput
('S~*ject has Uber booked already', 1) ('S~*ject has ~*er booked already', 2) Length of Tuple is: 2 S~*ject has ~*er booked alreadyre.escape()
Returns string with all non-alphanumerics backslashed, this is useful if you want to match an arbitrary literal string that may have regular expression metacharacters in it.
Syntax:
re.escape(string)Example:
- Python
OutputThis\ is\ Awesome\ even\ 1\ AM I\ Asked\ what\ is\ this\ \[a\-9\]\,\ he\ said\ \ \ \^WoW
re.search()
This method either returns None (if the pattern doesn’t match), or a re.MatchObject contains information about the matching part of the string. This method stops after the first match, so this is best suited for testing a regular expression more than extracting data.
Example: Searching for an occurrence of the pattern
- Python3
OutputMatch at index 14, 21 Full match: June 24 Month: June Day: 24
Match Object
A Match object contains all the information about the search and the result and if there is no match found then None will be returned. Let’s see some of the commonly used methods and attributes of the match object.
Getting the string and the regex
match.re attribute returns the regular expression passed and match.string attribute returns the string passed.
Example: Getting the string and the regex of the matched object
- Python3
Outputre.compile('\\bG') Welcome to GeeksForGeeksGetting index of matched object
- start() method returns the starting index of the matched substring
- end() method returns the ending index of the matched substring
- span() method returns a tuple containing the starting and the ending index of the matched substring
Example: Getting index of matched object
- Python3
Output11 14 (11, 14)
Getting matched substring
group() method returns the part of the string for which the patterns match. See the below example for a better understanding.
Example: Getting matched substring
- Python3
Outputme t

Comments
Post a Comment